Methods
Timeline of development for our model.
-

Oversampling Technique
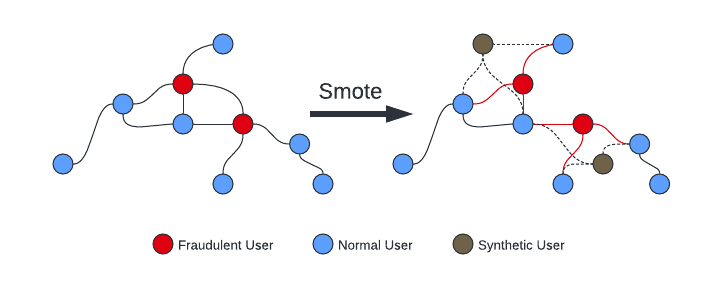
GraphSMOTE
We feed our imbalanced datasets into GraphSMOTE, which balances it by generating synthetic nodes. It addresses the imbalance by adding synthetic anomalous nodes to the graph, amplifying the minority class. These synthetic nodes maintain connections with existing nodes while preserving heterogeneity among links.
-

Introducing Sparsity
SparseGAD
GraphSMOTE alone doesn't fully capture the dissimilarity of anomalous nodes with their connected users. To address this, SparseGAD introduces sparsity, utilizing a learnable adjacency matrix ("homey" matrix) derived from cosine similarity calculations. This matrix helps identify whether connected nodes are similar or dissimilar, enhancing the model's ability to detect anomalous nodes exhibiting heterophilic behaviors.
-
GNN Models
GCN, GAT, GraphSage
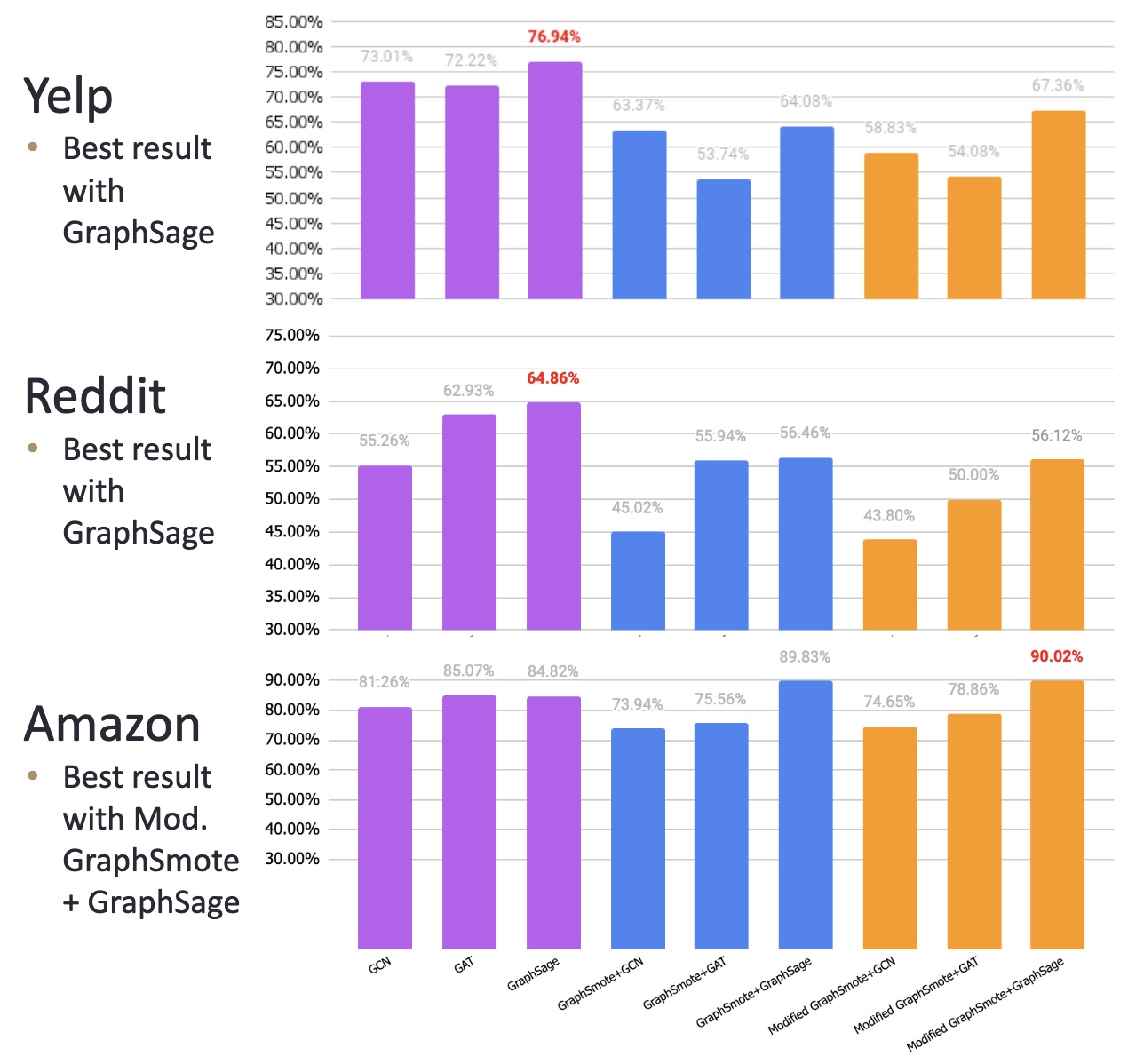
Upon applying these techniques, we feed in the output to our GNNs to obtain a result. The 3 GNNs we use are Graph Convolutional Networks (GCN), Graph Attention Networks (GAT), and GraphSage. We utilize different preprocessing technique, or "paths" before applying these GNN models. The main 3 paths, as well as a description of these 3 GNN models will be discussed in detail in the Implementation section.
-
Decision Phase
Fraudulent or Not
Finally, we use the trained GNN model to classify nodes as either fraudulent or non-fraudulent based on their features and neighborhood structure. We evaluate the model’s performance using the ROC-AUC score based on its ability to correctly identify anomalies in the dataset.
 In short:
In short:
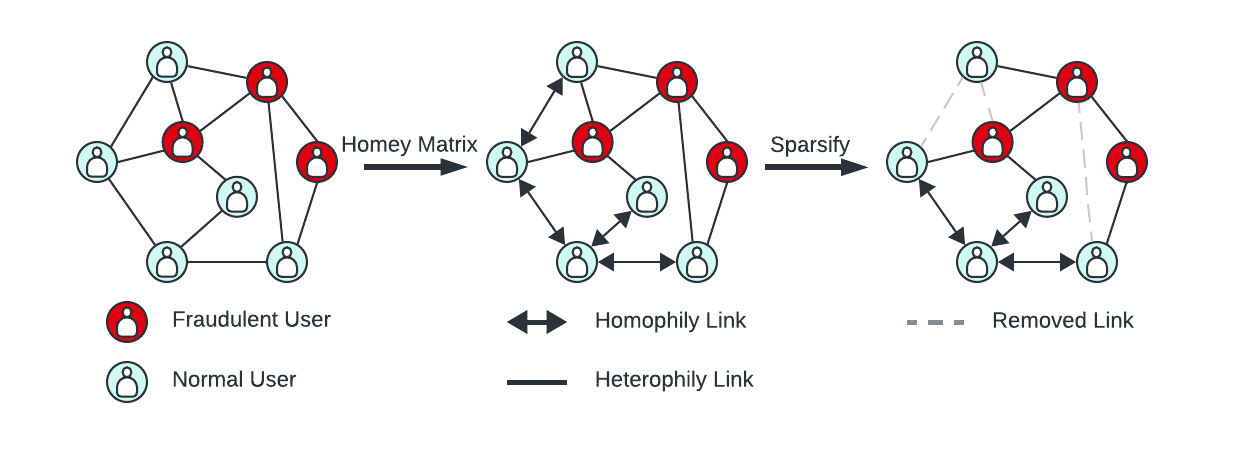 In short:
In short:
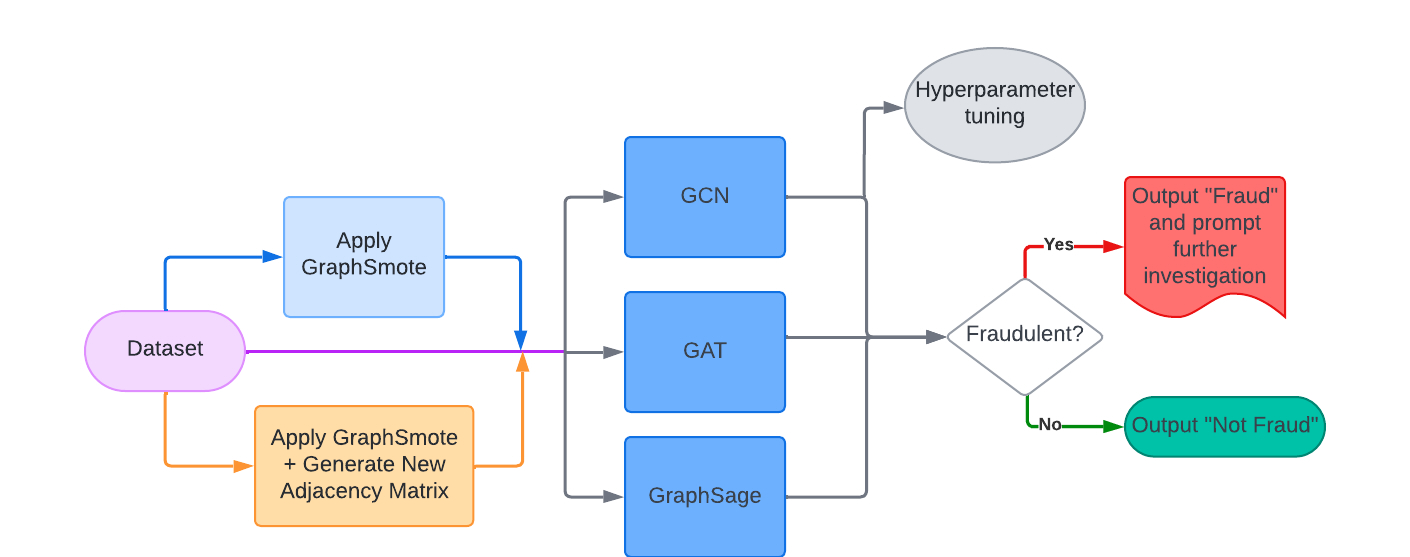 In short,
In short,